
脚本的诞生源自这里python 爬虫求助
脚本内存和CPU占用很低!
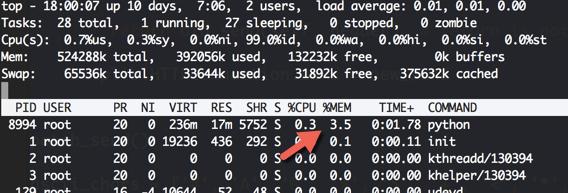
回答问题时我的脚本已经完成了60%,昨天凌晨加班完成了,使用到了ORC解析验证码,指定只分析数字!
使用前需要安装很多库,如果需要orc识别,还需要需要你的系统安装Tesseract-OCR,系统是linux的话在这里应该能找到编译好的包,老高用mac一句话就装好了brew install tesseract。
requirements.txt
progressbar == 2.3
pyquery == 1.2.9
requests == 2.4.3
Pillow == 2.8.2
可选:
pytesseract = 0.1.6
PIP一键安装依赖
pip install requests progressbar pyquery Pillow pytesseract
可能需要安装的包,用来解决lxml的安装问题!
yum install libxslt-devel libxml2-devel -y
# or
apt-get install libxml2-dev libxslt1-dev -y
测试平台
OSX centos python 2.6 2.7
使用方法
yunfile_downloader -u xxx -p /tmp/download -adb
-u 下载地址
-a 自动上传(需要bypy配合)
-b 后台下载
-d debug
-p 下载路径 (默认当前文件夹)
# 后台下载查看进度
tail -f /tmp/yunfile.log
获取代码
git clone https://gist.github.com/3aa1338b9f4a27b73270.git
获取bypy